原文发布于 CSDN:https://blog.csdn.net/m0_49683806/article/details/139253975
一.内容概述
- 上节课介绍了 model-base 的方法,这节课将介绍 model-free 的方法,上节课的 policy iteration 的方法是这节课的基础,我们把 policy iteration 当中基于模型的部分替换成不需要模型的部分就得到了今天的算法。
- 在这门课中,把 value iteration 和 policy iteration 统称为 model-base reinforcement learning,但是更准确来说,它们应该称为动态规划(dynamic programming)的方法。model-base reinforcement learning 简称 MBRL,这个研究的是我用数据估计出一个模型,再基于这个模型进行强化学习。
- 这节课介绍没有模型的强化学习方法,首先我们要学习随机变量的期望值,因为之前提到的 state value 和 action value 全都是随机变量的期望值,对随机变量采样的平均值可以作为 E[X] 的一个很好的近似。所以没有模型要有数据,没有数据要有模型才能学习。
课程大纲:
1.激励性实例(Motivating examples):介绍蒙特卡洛估计(Mento Carlo Estimation)的基本思想
2.介绍三个基于蒙特卡洛(MC)强化学习的算法(这三个算法环环相扣,前一个是后一个的基础)
(1)最简单的基于 MC 的 RL 算法:MC basic(我们把上节课介绍的 policy iteration 方法当中基于模型的部分替换成不需要模型的部分(依赖于数据的)就得到了这个算法。是最简单的基于蒙特卡洛强化学习的算法,简单到这个算法在实际中不能用,因为效率很低,但他有利于揭示怎么样把模型给去掉,不基于模型来实现强化学习的这样一个核心idea,即它可以帮助理解之后的,因为强化学习是一环扣一环的)
(2)更高效地使用数据:MC Exploring Starts(把 MC basic 复杂化)
(3)MC 没有探索就启动:Algorithm: MC ε-Greedy(去除掉 exploring starts 这样的 assumption)

二.激励性实例(Motivating examples)
从 model-based 强化学习过渡到 model-free 的强化学习,最难以理解的就是我们如何在没有模型的情况下去估计一些量?(How can we estimate something without models)
最简单的方法:蒙特卡洛估算(Monte Carlo estimation)。
下面通过一个例子说明蒙特卡洛估算: 投掷硬币
投掷硬币后的结果(正面或背面朝上)用随机变量(random variable) X 表示
- 如果结果为正面朝上,则 X = +1
- 如果结果是背面朝上,则 X = -1
目的是计算 (X 的平均数,X 的期望)。
这里有两种方法计算期望
- 方法 1 :基于模型的(model-based)
假设概率模型为(我们知道随机变量(random variable) X 的概率分布(probability distribution)):正面朝上和背面朝上的概率都是 0.5
那么随机变量(random variable) X 它的期望(expectation)就可以简单的通过定义计算:
**问题:**可能无法知道精确的概率分布情况(precise distribution)!!
- 方法 2 :无模型的(model-free)
基本思想:多次掷硬币,做很多次实验,得到很多的采样,然后计算所有采样的平均结果。
假设我们做了 N 次实验,这 N 次的实验结果分别是 ,得到一个样本序列: 。那么,均值可以近似为:
期望(expectation)用 来近似,认为 是
这就是蒙特卡洛估计的基本思想!
**问题:**用蒙特卡洛估计(Mento Carlo Estimation)是否精确?
- 当 N 较小时,近似值不准确。
- 随着 N 的增大,近似值会越来越精确。
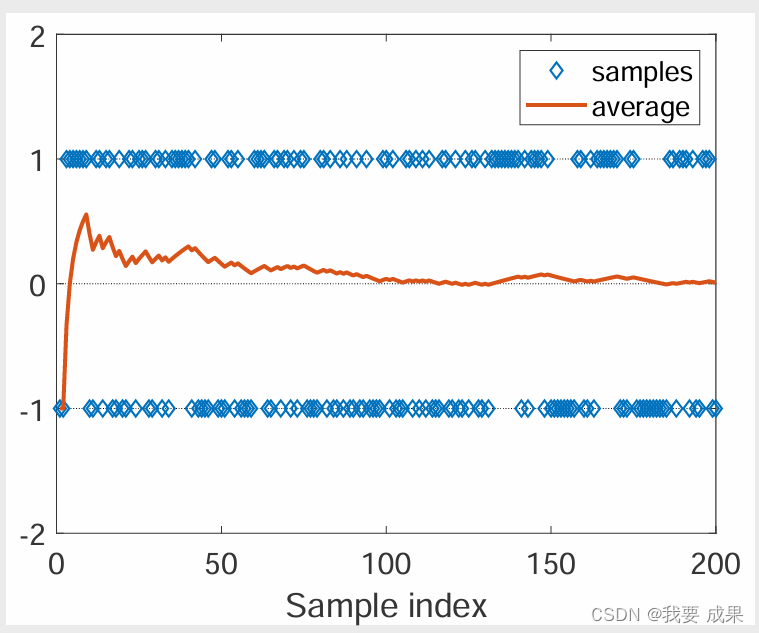
如上图所示,我们已知真实的期望(expectation)是 0,随着做平均的样本数越多,样本的平均值(expectation)越接近真实的期望(expectation)0
上面这样直观的解释有数学理论做支撑(大数定律 Law of large Numbers)
iid:独立同分布样本(independent and identically distributed sample)

总结:
- 蒙特卡罗估计是指依靠重复随机抽样来解决近似问题的一大类技术。凡是需要做大量的采样实验,最后用实验的结果近似的的方法,都可以称为蒙特卡洛估计的方法。
- 我们为什么要关注蒙特卡罗估计?因为它不需要模型!
- 为什么要关注均值估计(mean estimation)?为什么用蒙特卡洛来估计期望(expectation)?
- 因为状态值(state value)和行动值(action value)被定义为随机变量的期望值(expectation)!
三.最简单的基于 MC 的 RL 算法:MC basic
1.将策略迭代转换为无模型迭代(Convert policy iteration to be model-free)
理解算法的关键是理解如何将策略迭代算法(policy iteration algorithm)转换为无模型算法(model-free)。我们知道策略迭代算法(policy iteration algorithm)是依赖于模型的,但是实际上我们可以把它依赖于模型的那部分给替换掉,替换成 model-free 的模块
- 应充分理解策略迭代(policy iteration algorithm)。
- 应理解蒙特卡罗均值估计(Monte Carlo mean estimation)的思想。
接下来看策略迭代算法(policy iteration algorithm)如何转换为无模型(model-free)的:
策略迭代(policy iteration algorithm)的每一次迭代都有两个步骤:
- 1.策略评估:我有一个策略 ,通过求解贝尔曼公式,我要求出来它的状态值(state value)
- 2.策略改进:知道 之后就可以做改进,求解一个最优化问题得到一个新的策略 。(通过选择最大的 得到新的策略 )

这里面非常核心的量是
要计算动作值(action value) 有两种算法:
**方法 1 需要模型:**这就是 value iteration 这个算法所使用的,第一步得到了 ,第二步这些概率模型都是知道的,所以就可以求出来 (这些概率代表系统的模型)



