原文发布于 CSDN:https://blog.csdn.net/m0_49683806/article/details/139198327
学习引用
【强化学习的数学原理-赵世钰】课程笔记(三)贝尔曼最优公式
【强化学习的数学原理】课程:从零开始到透彻理解(完结)
内容梗概
1. 第三章主要有两个内容
(1)核心概念:最优状态值(optimal state value)和最优策略(optimal policy)。强化学习的目的就是寻找最优策略。
- 最优策略定义:我沿着这个策略能得到最大的状态值,沿着其他所有策略得到的状态值都没他大。
(2)基本工具:贝尔曼最优方程/公式(Bellman optimality equation)(BOE):贝尔曼最优公式和最优策略有关系,使用贝尔曼最优公式分析最优策略,贝尔曼最优公式可以求解出最优策略和最优的 state value。
- 使用不动点原理分析,这个不动点原理告诉我们这个式子两个方面的性质:
- 第一个方面是我要求解最优策略,最优 state value,那么它们到底是否存在呢,这种存在性非常重要。虽然存在但是最优的策略不一定是唯一的,但是最优的状态值是唯一的,最优的策略可能是确定性的 deterministic,也可能是随机性的 stochastic;
- 另外一个方面是他能给出一个算法求解贝尔曼最优公式,把这个公式求解出来了自然就得到了最优的策略和最优的 state value,强化学习的目标也就达到了
2. 第二章大纲
(1)激励性实例(Motivating examples)
(2)最优状态值(optimal state value)和最优策略(optimal policy)的定义
(3)贝尔曼最优公式(BOE):简介
(4)贝尔曼最优公式(BOE):右侧最大化
(5)贝尔曼最优公式(BOE):改写为
(6)收缩映射定理(Contraction mapping theorem)
(7)贝尔曼最优公式(BOE):解决方案
(8)贝尔曼最优公式(BOE):解的最优性
(9)分析最优策略(Analyzing optimal policies)
二.激励性实例(Motivating examples)
绿色箭头代表策略
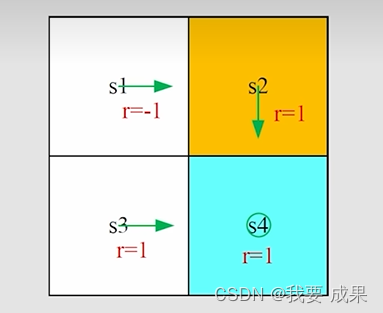
贝尔曼公式:
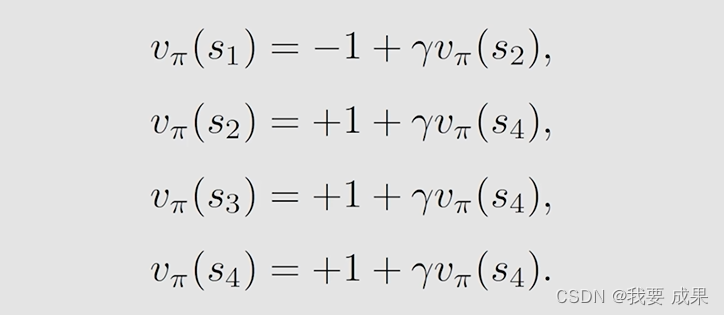
状态值(state value): 设 。那么可以计算出:
动作值(action value)可以通过状态值计算,或者根据第二章公式计算:考虑 ,共有 5 个 action ,每个 action 都有一个 state value 。
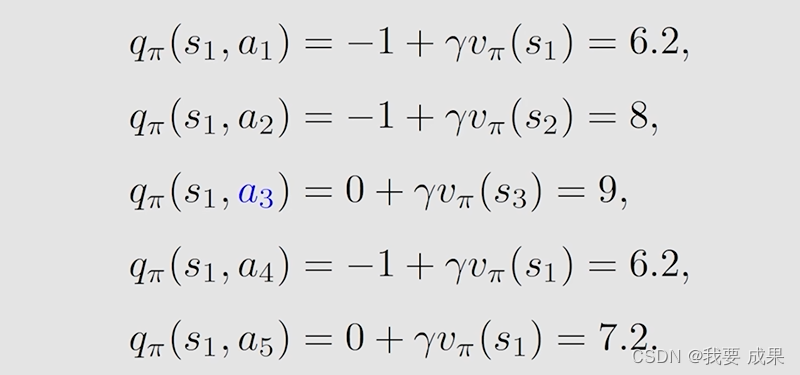
问题: 当前的策略(policy)不好,因为在 的时候往右走了,进入禁区,那么如何改进?
答案: 我们可以根据动作值(action value)改进策略(policy)。
具体来说,当前策略 是:
在这个策略下我们已经计算出来了 action value,观察我们刚才获得的动作值(action value):
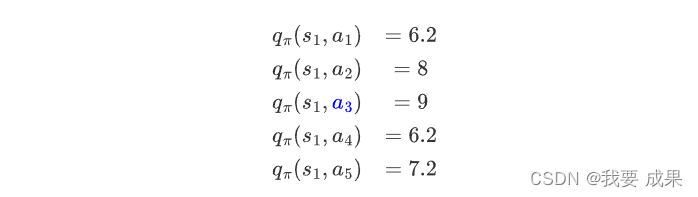
我们发现 对应的动作值(action value)最大,那么能不能选择 作为一个新的策略呢。如果我们选择最大的动作值(action value)呢?那么,新策略(policy)就是:
其中: 在 时最大
其中, 对应 action value 最大的那个 action,在这个例子里面是
问题: 为什么选择 action value 最大的 action 这样做能改进策略?
- 直觉:动作值(action value)可用于评估动作,动作值本身就代表了 action 的价值,如果选择一个 action ,他的 action value 很大,意味着之后能得到更多的 reward,相应策略也比较好。
- 数学:并不复杂,将在本讲座中介绍。
只要我们一遍一遍去做,不断迭代,最后一定会得到一个最优策略。也就是说,首先对每个状态都选择 action value 最大的 action,选择完了一次,然后再来一次迭代得到一个新的策略,再迭代得到一个新的策略,最后那个策略一定会趋向一个最优的策略
三.最优策略(optimal policy)的定义
状态值(state value)可用于评估策略好或者不好:如果有两个策略 和 ,它们在每个状态都有自己的状态值(state value),如果对所有的状态 , 得到的 state value 都大于 得到的 state value,则 比 “更好”。



