原文发布于 CSDN:https://blog.csdn.net/m0_49683806/article/details/137272667
一. 内容概述
第一部分主要有两个内容:
1. 通过案例介绍强化学习中的基本概念
2. 在马尔可夫决策过程(MDP)的框架下将概念正式描述出来
二. 通过案例介绍强化学习中的基本概念
1. 网格世界(A grid world example)
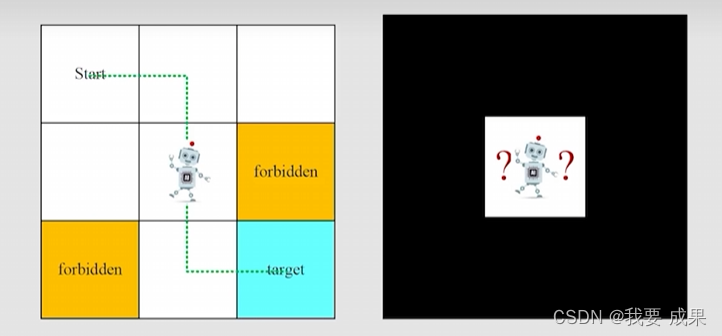
本课程中始终使用的一个示例:网格世界
(1)网格类型:可访问(Accessible);禁止访问(forbidden);目标单元格(target cells);边界(boundary)
(2)机器人只能在相邻网格移动,不能斜着移动
强化学习的任务:给任意一个起始点,找到一个比较好的路径到达目标。比较好的路径就是尽量避开禁止访问的地方,不要有无意义的拐弯,不要超越边界。
2. 状态(State)
状态(state):智能体相对于环境的状态
以网格世界为例,智能体的位置就是状态。有九个可能的位置,因此也就有九种状态:。这些字母是一个索引,真正对应的状态可能是在二维平面上的位置(x,y),更复杂的问题可能还会对应速度,加速度,或其他类型的状态信息等等。
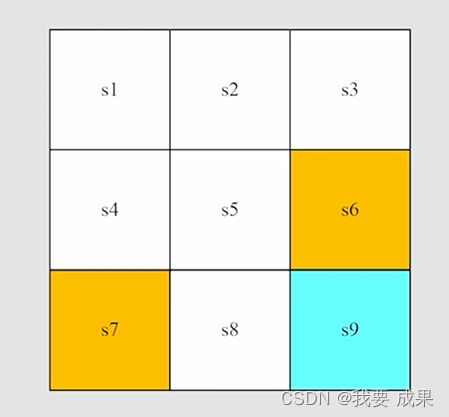
状态空间(state space):把所有状态放在一起,所有状态的集合(set)
3. 动作(Action)
动作(action):每个状态都有五种可能的行动: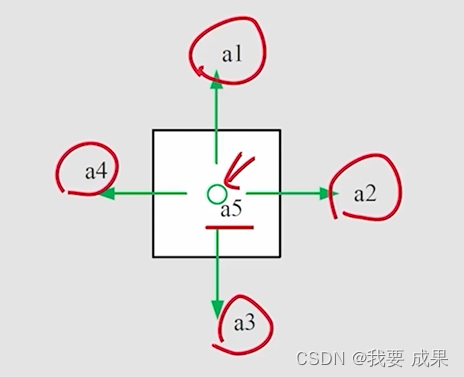
- :向上移动;
- : 向右移动;
- : 向下移动;
- : 向左移动;
- : 保持不变;
状态的动作空间(action space):状态的所有可能动作的集合。
动作空间和状态有依赖关系,不同状态的动作空间不同,由上面的公式可知,A 是 的函数。
4. 状态转移(State transition)
在采取行动(action)时,智能体可能会从一个状态移动到另一个状态。这种过程称为状态转移。
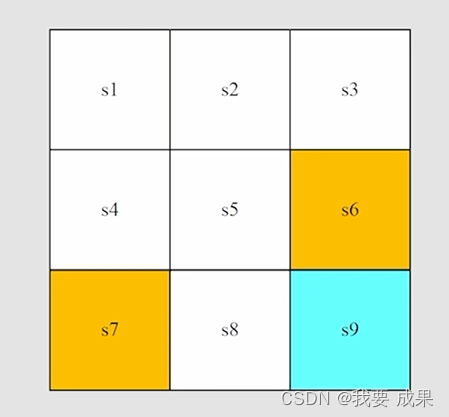
- 在状态 下,如果我们选择行动 ,那么下一个状态是什么?(向右移动一格)
- 在状态 下,如果我们选择行动 ,那么下一个状态是什么?(向上移动一格,会撞到边界,所以状态还是 )
状态转换描述了智能体与环境的交互行为。 在游戏当中可以任意定义某个状态采取一个行动后状态的转换,但是在实际中不可以。
注意禁止访问的区域(forbidden area):
例如:在状态 ,如果我们选择操作 、 那么下一个状态是什么?
- 情况 1:禁区可以进入,但会受到惩罚。那么
- 情况 2:禁区无法进入(如被围墙包围)
这边考虑的是第一种情况,这种情况更为普遍,也更具挑战性。因为如果把一些状态给排除掉的话,状态空间就小了,实际上做搜索的时候会更加容易。虽然进去forbidden area会的得到惩罚,但是也许进去之后,进到target area反而是最近的路径,所以有可能agent会冒险进到这个forbidden area。
表格表示法(Tabular representation): 使用表格来描述状态转换,表格的每一行对应状态(state),每一列对应行动(action)。
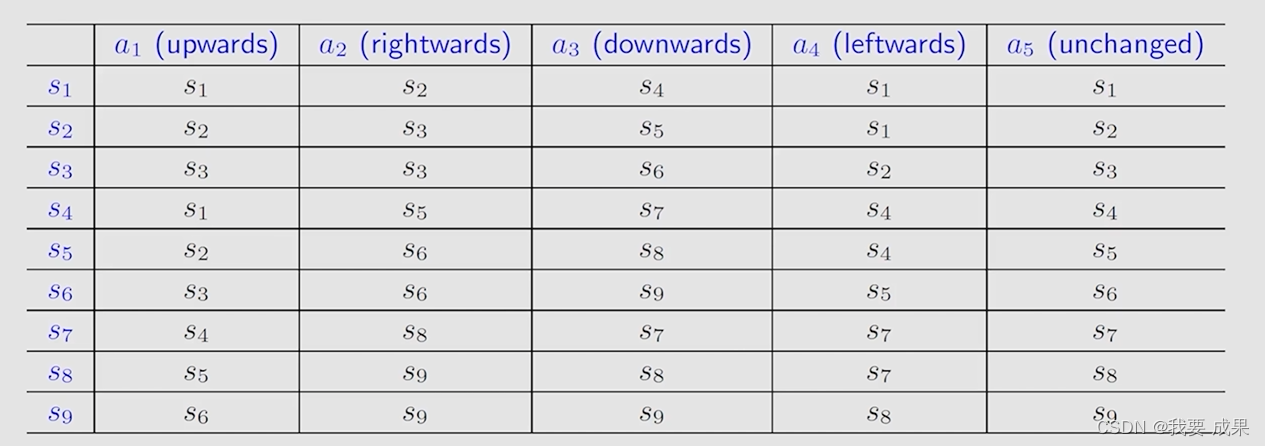
表格表示法只能表示确定性(deterministic)的情况。
State transition probability: 使用概率描述状态转换
- 直觉:在状态 下,如果我们选择行动(take action),下一个状态就是 。
- 数学:使用条件概率表示



