1.hadoop集群搭建及使用
(1).集群规划;

(2).虚拟机准备;
1、创建虚拟机(具体步骤不再展示);
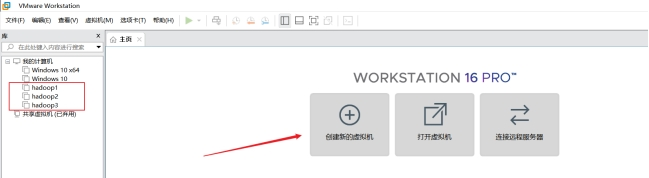
2 、配置网络;
ping外网:ping baidu.com
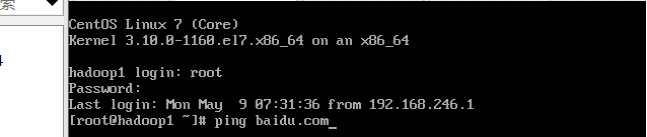
如果ping不通
修改如下文件:
vi /etc/sysconfig/network-scripts/ifcfg-ens33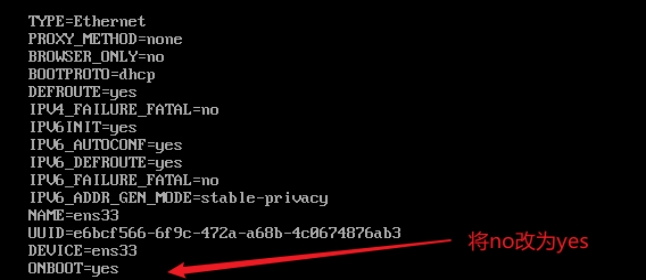
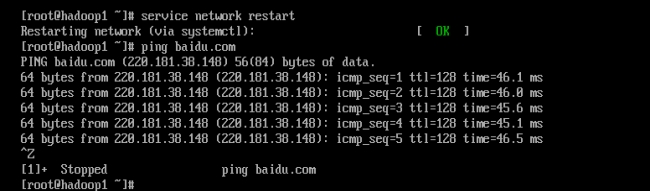
重启网络服务:
service network restart
配置静态IP:
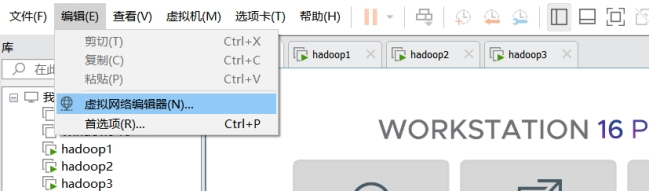
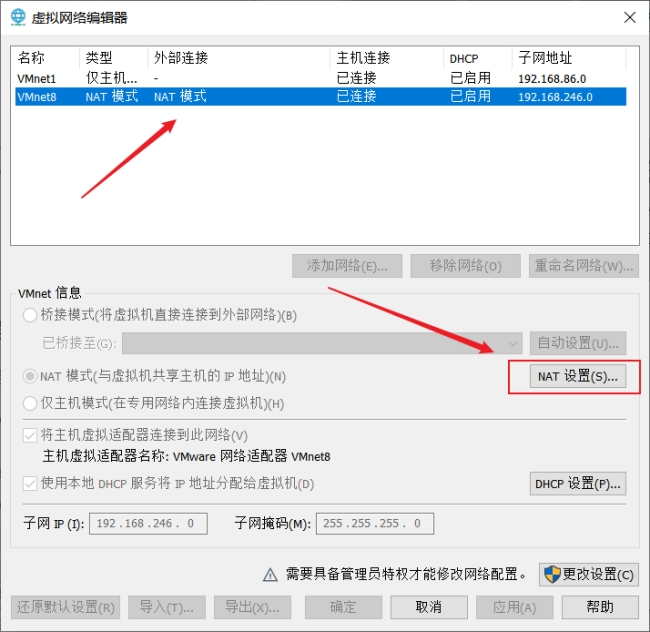
打开VMware->编辑->虚拟机网络编辑器

查看IP:ip addr

修改网卡的配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
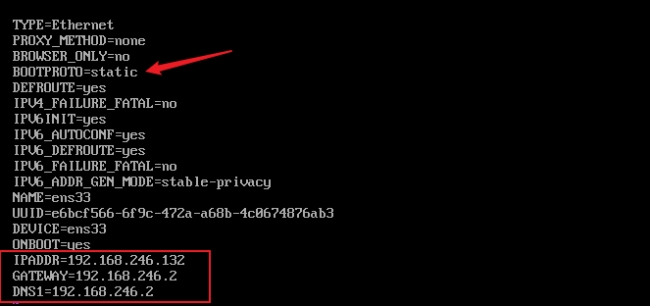
#修改并添加:(IP为静态)
BOOTPROTO=static
IPADDR=192.168.246.132
GATEWAY=192.168.246.2
DNS1=192.168.246.2如图所示
重启网络服务:service network restart
ping外网(查看是否可以ping通):ping baidu.com
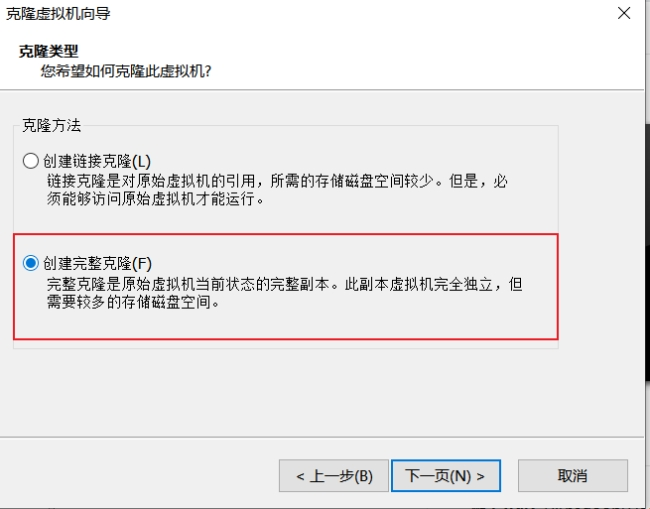
3).克隆两台上述已配置的虚拟机;
关闭虚拟机:
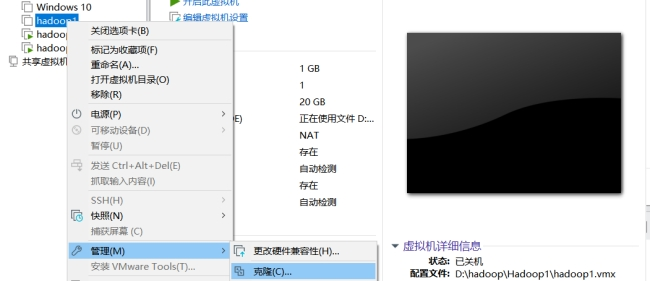
点击下一页,
选择克隆类型时,创建完整克隆:
#打开第二、三台虚拟机,进入:
vi /etc/sysconfig/network-scripts/ifcfg-ens-33
#更改
IPADDR=192.168.246.133
IPADDR=192.168.246.134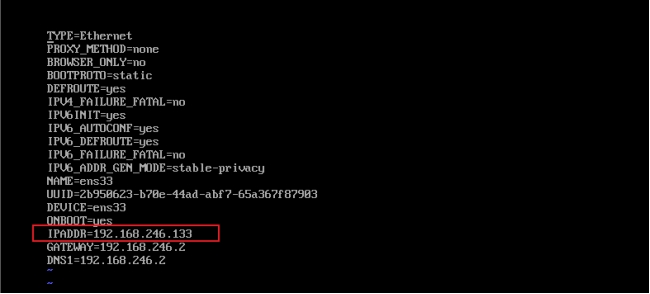
重启网络服务并查看是否可以ping通外网。
(3).修改主机名;
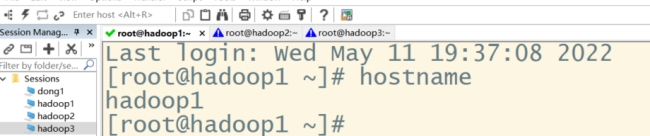
查看主机名:hostname
修改第一台主机名:sudo hostnamectl set-hostname hadoop1
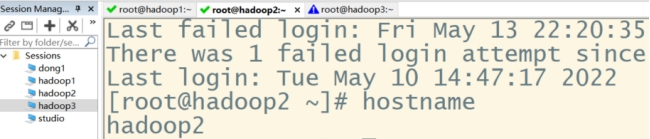
修改第二台主机名:sudo hostnamectl set-hostname hadoop2
修改第三台主机名:sudo hostnamectl set-hostname hadoop3

三台都要修改ip与主机名的映射:sudo vi /etc/hosts
#添加:
192.168.246.132 hadoop1
192.168.246.134 hadoop2
192.168.246.133 hadoop3
重启虚拟机生效:reboot
(4).配置免密登录
在hadoop1机器上操作:ssh-keygen -t rsa
执行命令后,连续敲击三次回车键,生成公钥
#拷贝公钥:
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3由于我已拷贝过,所以显示已存在

进入hadoop2、hadoop3同样操作,实现可以使用ssh hadoop2、ssh hadoop3,不需要密码就能进入hadoop2、hadoop3
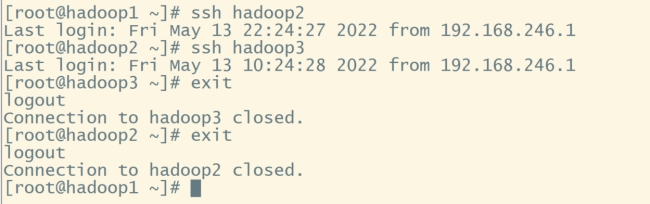
(5).编写分发脚本;
输入:rsync —help

#三台虚拟机安装rsync命令:
sudo yum install rsync -y
#rsync与scp区别:用rsync做文件的复制比scp快,rsync只对差异文件作更新
#在主目录创建bin目录:
mkdir ~/bin
#创建分发脚本脚本:
vim ~/bin/xsync脚本内容如下:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
#注意,如果你的主机名命名和我不一样,下面这三个更换成你的主机名
for host in hadoop1 hadoop2 hadoop3
do
echo ================= $host =================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=(dirname $file); pwd)
fname=file)
ssh pdir"
rsync -av fname pdir
else
echo $file does not exists!
fi
done
done 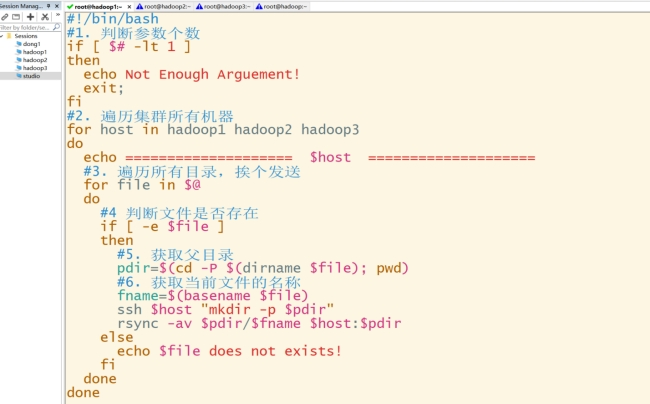
#修改权限:
chmod +x ~/bin/xsync
#测试:把xsync命令发送到hadoop2、hadoop3
#进入目录:
cd ~/bin
#将xsync脚本发送到hadoop2、hadoop3:
xsync xsync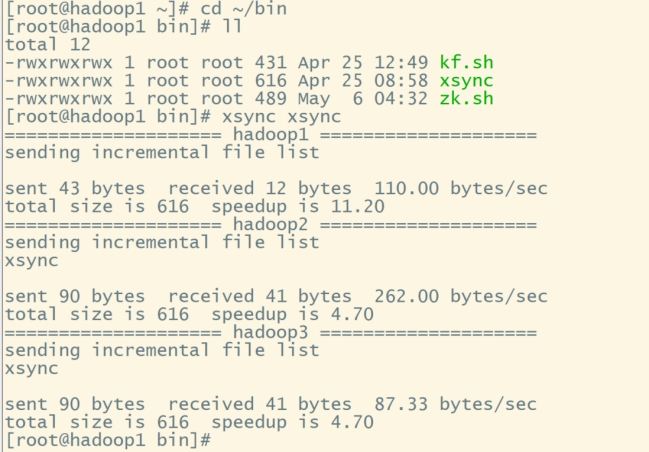
(6).安装JDK;
进入官网下载匹配的jdk8安装包,上传至linux:cd
mkdir soft
mkdir installfile
cd ~/installfile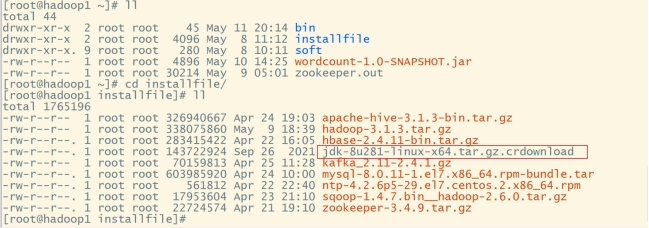
#解压:
tar -zxvf jdk-8u281-linux-x64.tar.gz.crdownload -C ~/soft
#切换到soft目录下:
cd /root/soft
#创建软连接:
ln -s jdk1.8.0_281 jdk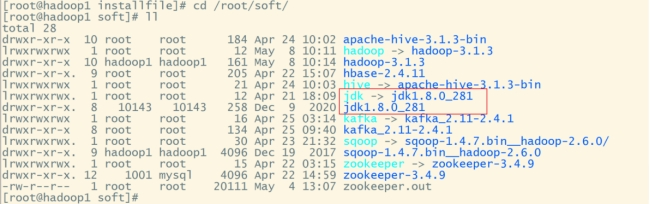
#配置环境变量:
vi ~/.bashrc
#内容如下:
export JAVA_HOME=~/soft/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:{JAVA_HOME}</span>/lib:<span class="token variable">{JRE_HOME}/lib
export PATH={JAVA_HOME}</span>/bin:<span class="token environment constant">PATH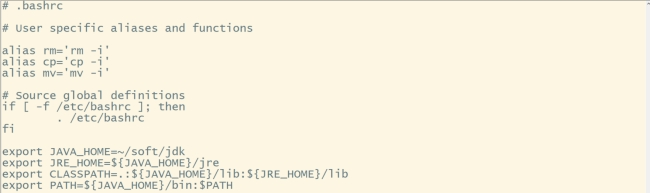
#让环境变量生效:
source ~/.bashrc
#验证:
java -version
进入hadoop2、hadoop3按照上述步骤配置jdk、环境变量并验证
(7).安装hadoop
#切换至installfile目录解压hadoop安装包:
cd /root/installfile
#解压至soft目录下
tar -zxvf hadoop-3.1.3.tar.gz -C ~/soft
#切换至soft目录:
cd /root/soft
#创建软连接:
ln -s hadoop-3.1.3 hadoop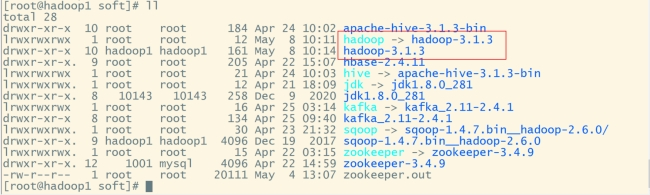
#配置环境变量:
vi ~/.bashrc
#内容如下:
export HADOOP_HOME=~/soft/hadoop
export PATH=HADOOP_HOME/bin:$HADOOP_HOME/sbin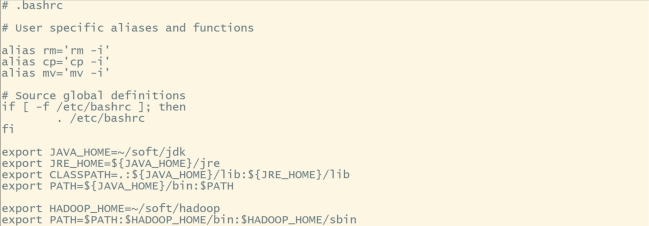
#让环境变量生效:
source ~/.bashrc
#验证:
hadoop version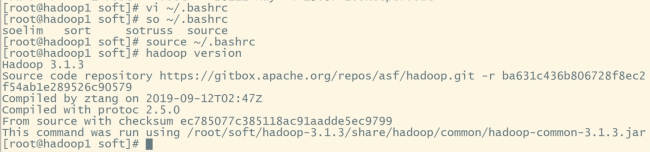
#进入hadoop配置目录:
cd $HADOOP_HOME/etc/hadoop
#在hadoop-env.sh中配置JAVA_HOME路径:
vi hadoop-env.sh
配置core-site.xml:vi core-site.xml
在和之间添加如下内容:
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop_data/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<!-- hadoop1的内网IP地址 -->
<value>hdfs://hadoop1:9000</value>
</property>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:8020</value>
</property>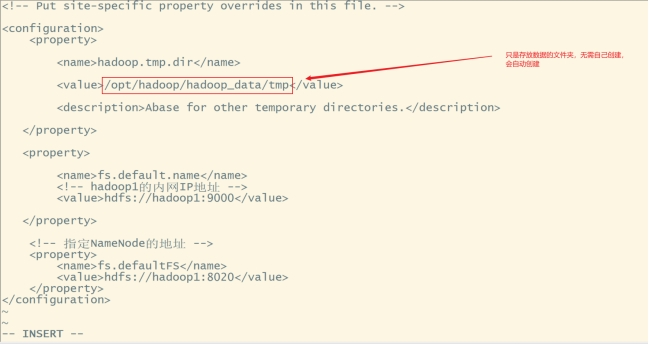
配置hdfs-site.xml:vi hdfs-site.xml
在和之间添加如下内容:
<!-- 指定NameNode的web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- 设置SecondaryNameNode(2NN)的web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:9868</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hhadoop_data/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop_data/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
<description>need not permissions</description>
</property>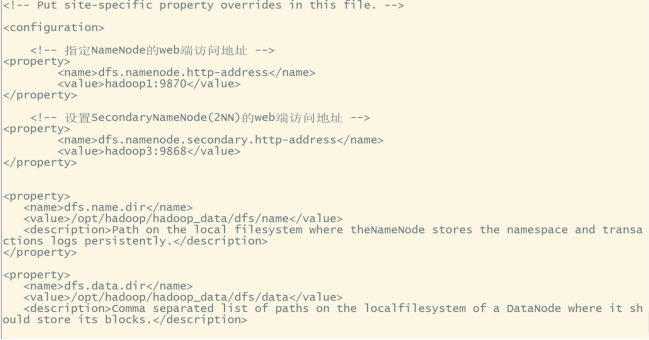

配置yarn-site.xml:vi yarn-site.xml
在和之间添加如下内容:
<!-- 指定MapReduce走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>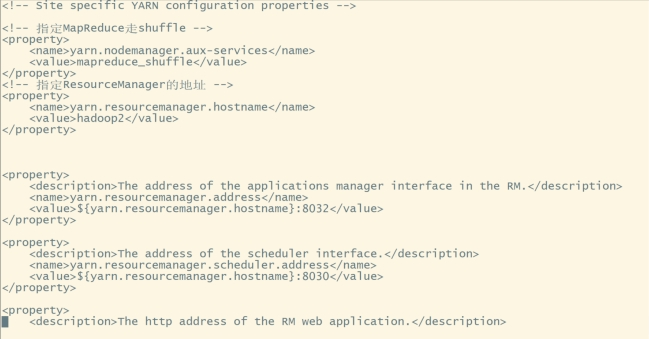


#复制并且配置mapred-site.xml:
cp mapred-site.xml mapred-site.xml.template
vi mapred-site.xml在和之间添加如下内容:
<!-- 指定MapReduce程序运行在Yarn上的地址 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hadoop1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/opt/hadoop/hadoop_data/var</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/root/soft/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/root/soft/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/root/soft/hadoop</value>
</property>
配置workers,将三个主机名添加进去:vi workers

#进入/sbin目录下:
cd /root/soft/hadoop/sbin/
#修改start-dfs.sh和stop-dfs.sh在这两个文件开头加如下内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root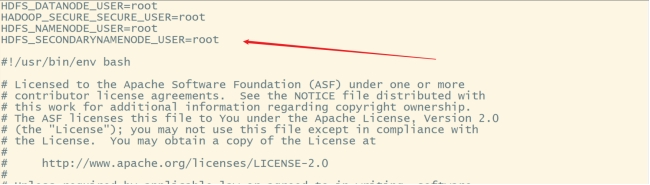
#修改start-yarn.sh和stop-yarn.sh在这两个文件开头加如下内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=root
YARN_NODEMANAGER_USER=root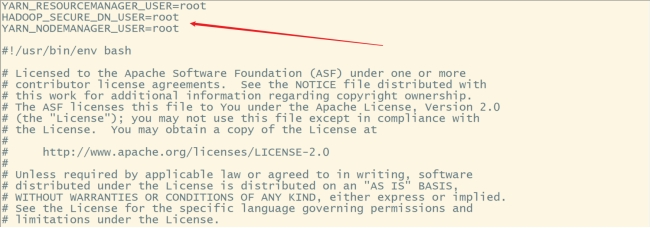
切换到soft目录下:cd /root/soft
使用xsync脚本将hadoop-3.1.3发送到hadoop2、hadoop3:

#切换hadoop2、hadoop3在soft目录下创建hadoop-3.1.3的软连接:
ln -s hadoop-3.1.3 hadoop
#配置hadoop环境变量:
vi ~/.bashrc
#内容如下:
export HADOOP_HOME=~/soft/hadoop
export PATH=HADOOP_HOME/bin:$HADOOP_HOME/sbin
#让环境变量生效:
source ~/.bashrc
#验证:
hadoop version

(8).启动hadoop
#格式化hadoop:
hadoop namenode -format注:hadoop只能格式化一次,在下面出现successfully formatted为格式化成功,这里由于我已经格式化了,就不附截图了。
在hadoop1启动hdfs:start-dfs.sh

在hadoop2启动yarn:start-yarn.sh

验证进程:
在hadoop1、hadoop2、hadoop3分别输入:jps



关闭防火墙:systemctl stop firewalld
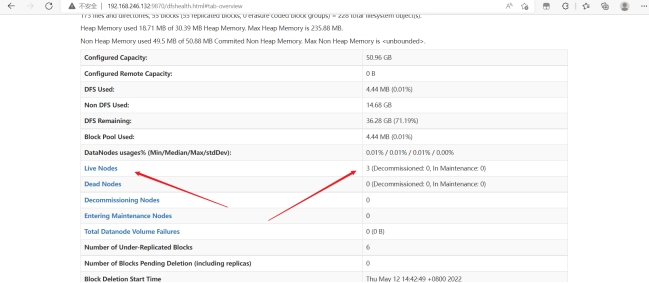
在浏览器输入:192.168.246.132:9870

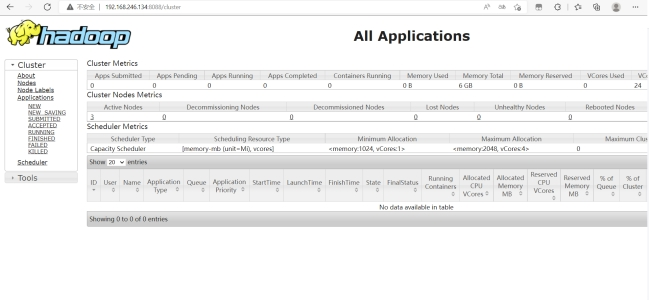
在浏览器输入:192.168.246.134:8088
在浏览器端可查看每台服务器状态:
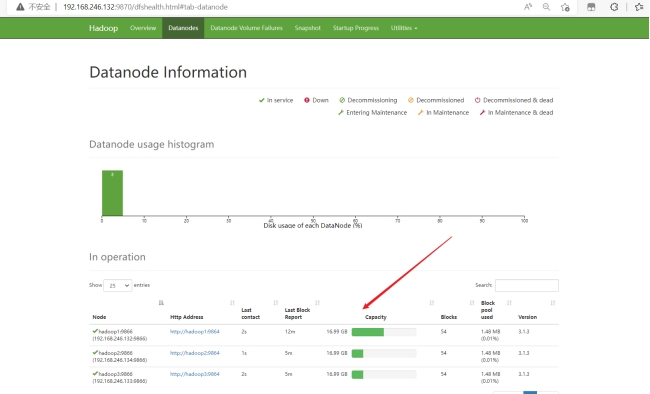
(9).简单使用hadoop
#查看hdfs的根目录:
hdfs dfs -ls /
#在根目录下创建文件夹:
hdfs dfs -mkdir /data
#将linux本地文件上传到hdfs:
hdfs dfs -put emp.csv /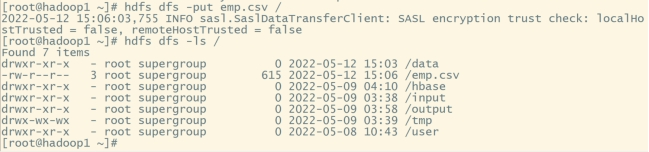
#移动emp.csv的位置到/data目录下:
hdfs dfs -mv /emp.csv /data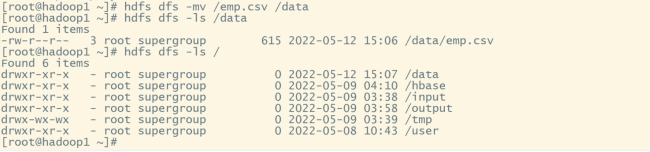
#将data目录下的emp.csv复制到hdfs的根目录下:
hdfs dfs -cp /data/emp.csv /emp-copy.csv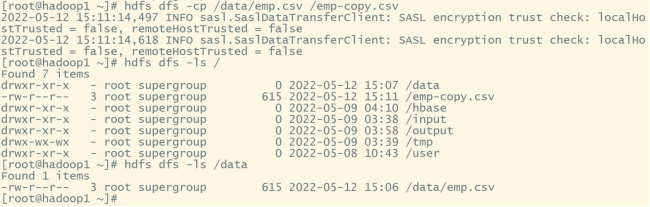
#查看emp.csv文件内容:
hdfs dfs -cat /emp-copy.csv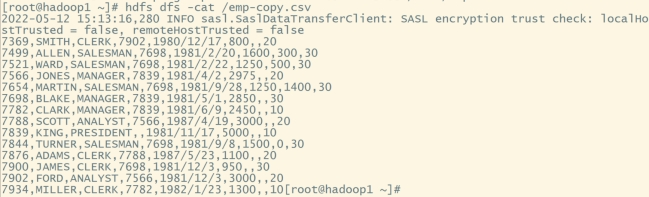
#删除文件emp-copy.csv:
hdfs dfs -rm /emp-copy.csv
#删除data文件夹:
hdfs dfs -rm -r /data

使用wordcount脚本(自己编写的),对某个文件里面的字符进行统计
在linux本地创建1.txt文件并上传到hdfs根目录下的input(上面已有步骤,直接附截图):


#运行脚本:
hadoop jar wordcount-1.0-SNAPSHOT.jar org.example.MyMain /input/1.txt /output/wordcount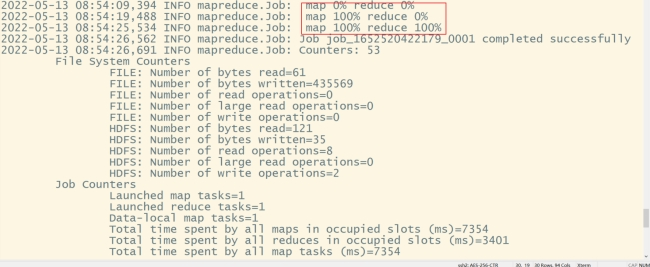
#查看结果:
hdfs dfs -cat /output/wordcount/part-r-00000
在浏览器界面(9870)也可查看hdfs的文件存放情况:
2.ZooKeeper集群搭建及使用
(1).下载zookeeper安装包并解压
tar -zxvf zookeeper-3.4.9.tar.gz -C ~/soft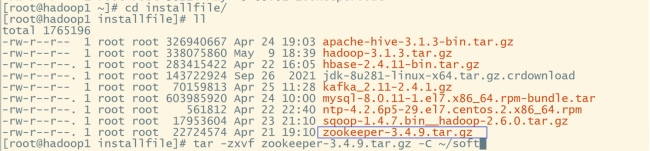
#切换至soft目录:
cd /root/soft
#创建软连接:
ln -s zookeeper-3.4.9 zookeeper
#同步zookeeper至其他机器:
xsync zookeeper-3.4.9切换hadoop2、hadoop3创建软连接
(2).配置环境变量
vi ~/.bashrc
#内容如下:
export ZOOKEEPER_HOME=/root/soft/zookeeper
export PATH=PATH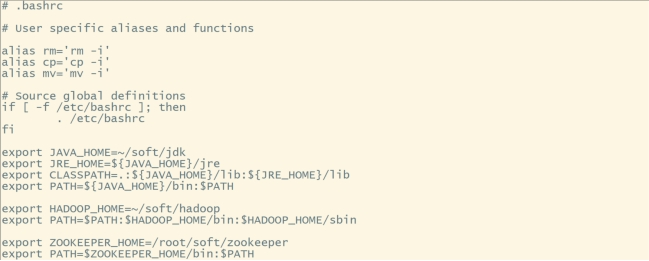
#让环境变量生效:
source ~/.bashrc每一台都需要配置环境变量,在hadoop2、hadoop3重复(2)步骤

(3).配置zoo.cfg
#进入conf目录:
cd zookeeper/conf/
#复制zoo_sample.cf:
cp zoo_sample.cfg zoo.cfg
#编辑zoo.cfg:
vi zoo.cfg
#修改:
dataDir=/root/soft/zookeeper/zkData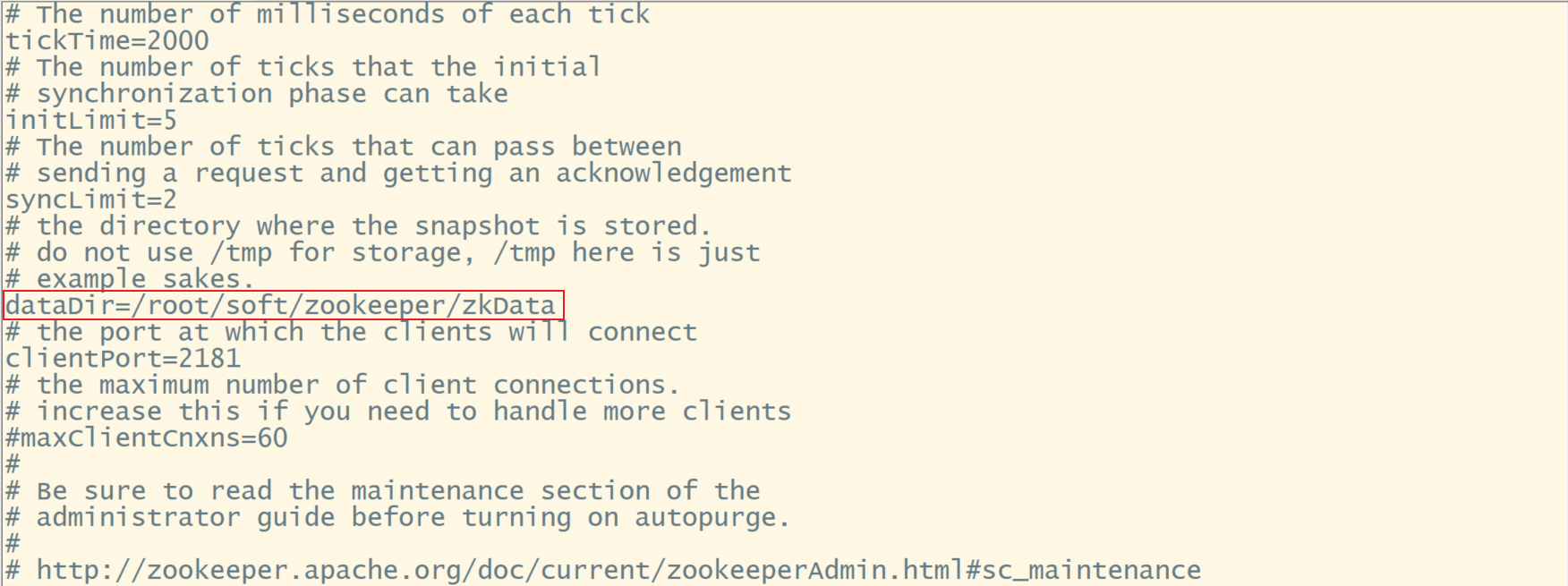
#末尾添加:
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
server.A=B: C: D。
A:机器编号
B:主机名
C: Leader与Follower的访问端口
D:选举Leader接口
#同步zoo.cfg:
xsync zoo.cfg配置服务器编号:
#进入zookeeper:
cd $ZOOKEEPER_HOME
#创建数据存放目录:
mkdir zkData
#编辑myid:.
vi zkData/myid内容为:1


在hadoop2中的myid添加内容为:2
在hadoop3中的myid添加内容为:3
(4).编写zookeeper脚本
#进入bin目录下:
cd ~/bin
#创建脚本:
vi zk.sh内容如下:
#!/bin/bash
case $1 in
"start"){
for i in hadoop1 hadoop2 hadoop3
do
echo " --------启动 $i zookeeper-------"
ssh $i "zkServer.sh start "
done
};;
"stop"){
for i in hadoop1 hadoop2 hadoop3
do
echo " --------停止 $i zookeeper-------"
ssh $i "zkServer.sh stop"
done
};;
"status"){
for i in hadoop1 hadoop2 hadoop3
do
echo " --------状态 $i zookeeper-------"
ssh $i "zkServer.sh status"
done
};;
esac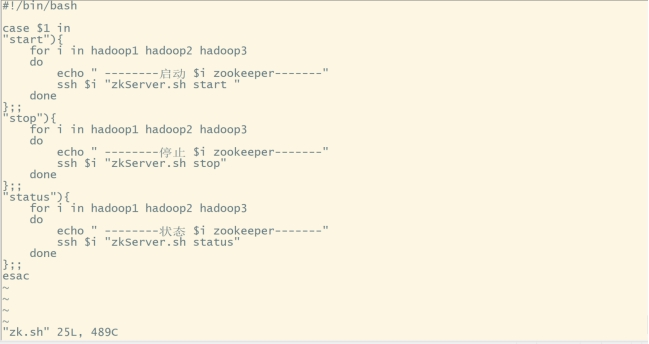
添加脚本执行权限:chmod u+x zk.sh

(5).启动zookeeper集群
#启动zookeeper集群(启动前先检查防火墙。没关的关一下):
zk.sh start
#查看各机器状态:
zk.sh status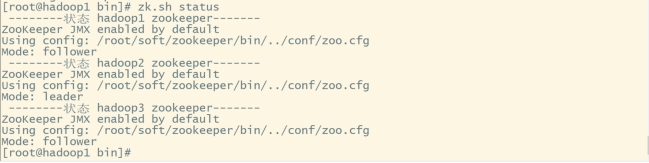
#停止zookeeper集群:
zk.sh stop
(6).zookeeper集群的简单使用
#启动zookeeper集群:
zk.sh start
#进入zookeeper命令行:
zkCli.sh
#创建节点(节点有四种类型,永久节点、临时节点、永久序列化节点、临时序列化节点):
# -s 序列化 -e 临时节点 path 创建路径 data 节点数据
create [-s] [-e] path data
#创建demo临时节点:
create -e /demo 321
#查看根下的所有节点:
ls /
#查看path下所有znode,以及zonde的属性:
ls2 /demo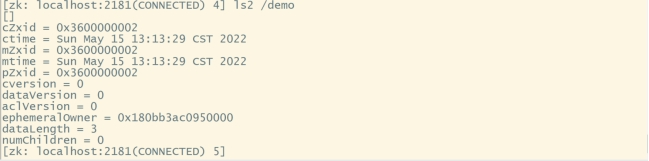
#拿到/demo的数据:
get /demo
#修改/demo的数据:
set /demo 456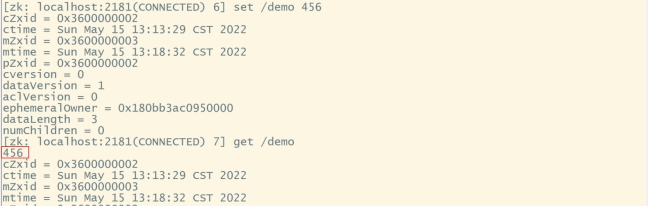
#递归删除节点:
rmr /demo
#查看历史记录:
history
#退出zookeeper命令行:
quit
3.HBase集群搭建及使用
(1).查看hbase与jdk、hadoop的版本匹配;
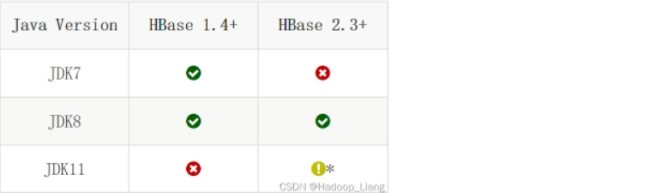
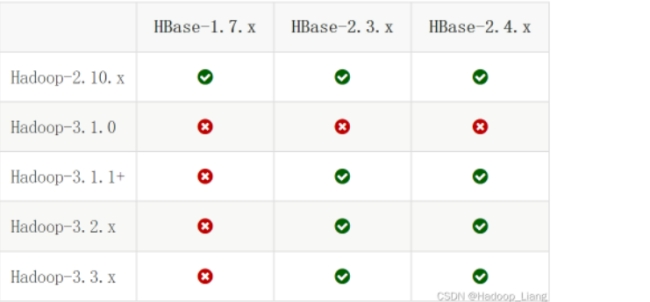
(2).集群规划

(3).下载、解压hbase安装包
#切换到installfile:
cd /root/installfile
#解压至soft目录下:
tar -zxvf hbase-2.4.11-bin.tar.gz -C ~/soft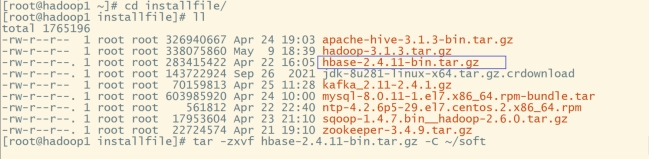
#切换至soft目录:
cd /root/soft
#创建软连接:
ln -s hbase-2.4.11 hbase
#同步zookeeper至其他机器:
xsync hbase-2.4.11
#切换hadoop2、hadoop3创建软连接(4).配置环境变量;
vi ~/.bashrc
#内容如下:
export HBASE_HOME=~/soft/hbase-2.4.11
export PATH=PATH
#让环境变量生效:
source ~/.bashrc
#验证:
hbase version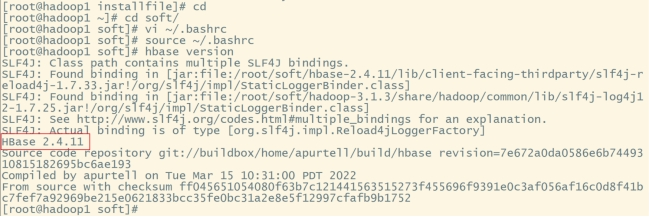
每一台都需要配置环境变量,在hadoop2、hadoop3重复(4)步骤
(5).配置hbase-site.xml
#切换到conf目录:
cd $HBASE_HOME/conf
#编辑hbase-site.xml:
vi hbase-site.xml
(先将原有配置全部删除)在和之间添加如下内容:
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/root/soft/zookeeper/zkData</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/root/soft/hbase-2.4.11/tmp</value>
</property>
<!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>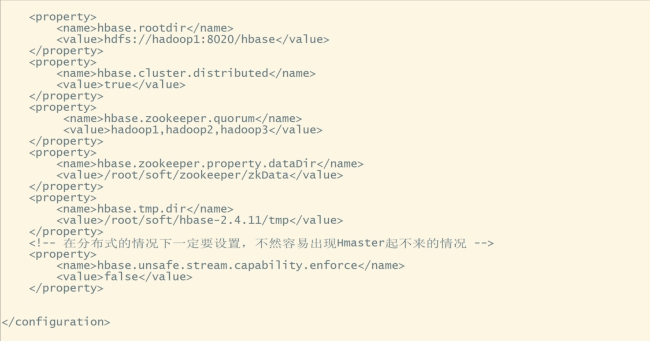
(6).配置regionservers
#编辑regionservers:
vi regionservers
#删除原有的localhost,添加如下内容:
hadoop1
hadoop2
hadoop3
(7).配置备用master
#编辑backup-masters:
vi backup-masters
#添加内容为:
hadoop2

(8).软连接hadoop配置文件到hbase配置目录并分发hbase;
#软连接hadoop的core-site.xml到hbase:
ln -s /root/soft/hadoop/etc/hadoop/core-site.xml core-site.xml
#软连接hadoop的hdfs-site.xml到hbase:
ln -s /root/soft/hadoop/etc/hadoop/hdfs-site.xml hdfs-site.xml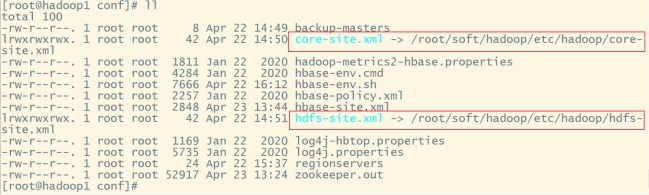
#返回上一级目录:
cd ..
#同步conf文件夹:
xsync conf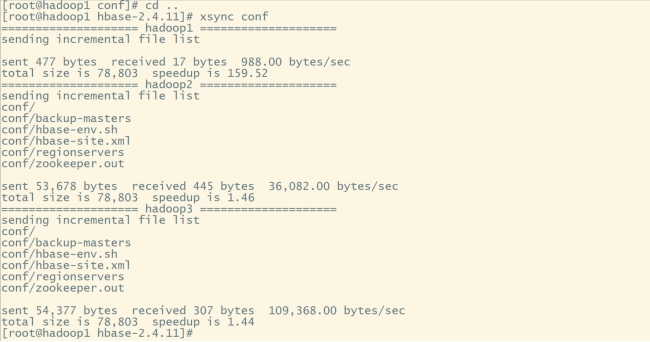
(9).启动hbase集群
#启动hbase前需要先启动zookeeper、hadoop:
zk.sh start
start-all.sh
start-hbase.sh
#或者分开启动hbase:
hbase-daemon.sh start master
hbase-daemon.sh start regionserver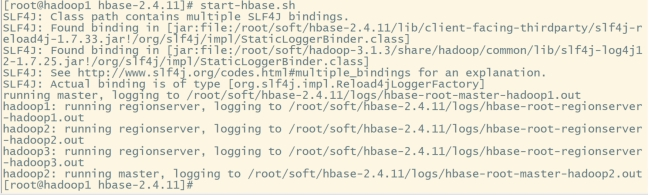
分别在hadoop1、hadoop2、hadoop3输入jps查看节点:jps




进入浏览器查看:192.168.246.132:16010
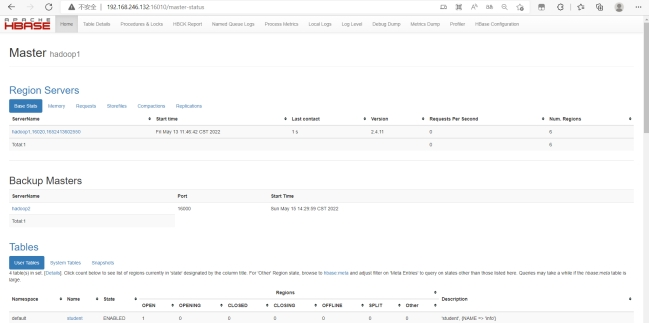
#停止hbase集群:
stop-hbase.sh
#如果无法关闭就分别关闭master、regionserver:
hbase-daemons.sh stop regionserver
hbase-daemons.sh stop master(10).hbase集群的简单使用;
#启动hbase集群:
start-hbase.sh
#进入hbase命令行:
hbase shell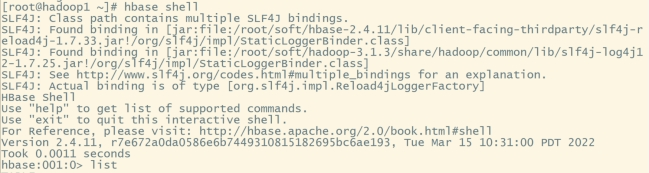
#查看所有表:
list
#创建stu表:
create 'stu','info','no'
#查看表结构:
describe 'stu'
#启用或禁用表:
is_enabled 'stu'
is_disabled 'stu'
#向stu表添加数据:
put 'stu','1001','info:name','HYX'
#扫描表数据:
scan 'stu'
#继续向stu表添加数据:
put 'stu','1002','info:name','Jack'
put 'stu','1002','info:age','22'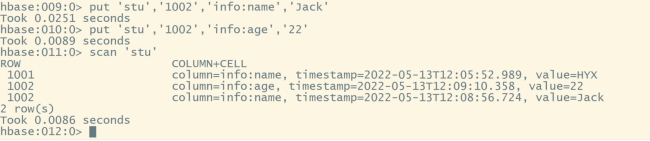
#统计表记录数:
count 'stu'
#删除stu表需要禁用表:
disable 'stu'
#删除表:
drop 'stu'
#退出hbase命令行:
exit 或 quit4.Kafka集群搭建及使用
(1).集群规划

(2).下载并解压安装包
#切换到installfile目录:
cd /root/installfile
#解压至soft目录下:
tar -zxvf kafka_2.11-2.4.1.gz -C ~/soft
#切换至soft目录:
cd /root/soft
#创建软连接:
ln -s kafka_2.11-2.4.1 kafka
#同步kafka至其他机器:
xsync kafka_2.11-2.4.1切换hadoop2、hadoop3创建软连接
(3).配置环境变量
vi ~/.bashrc
#内容如下:
export KAFKA_HOME=/root/soft/kafka
export PATH=KAFKA_HOME/bin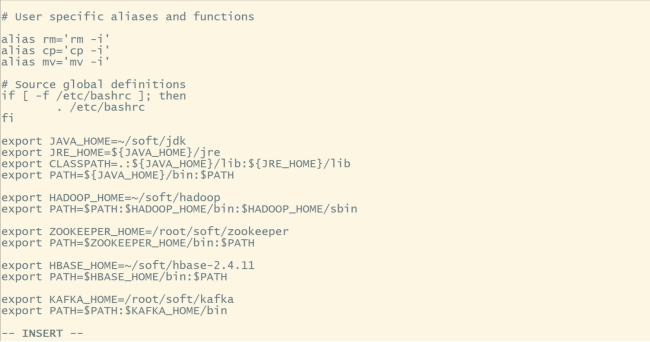
#让环境变量生效:
source ~/.bashrc每一台都需要配置环境变量,在hadoop2、hadoop3重复(3)步骤
(4).分别在三台机器上创建logs目录
#切换到kafka目录:
cd $KAFKA_HOME
#创建logs目录:
mkdir logs
(5).修改配置文件server.properties
#切换至config目录:
cd config
#编辑server.properties:
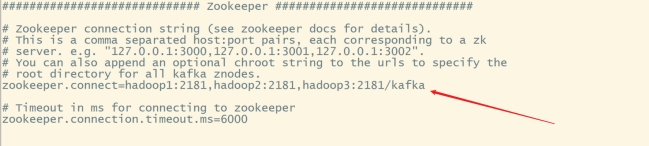
vi server.properties
#修改内容如下:
broker.id=0
#删除topic功能
delete.topic.enable=true
log.dirs=/root/soft/kafka/logs
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181/kafka

#分发server.properties到hadoop2、hadoop3:
xsync server.properties
#修改hadoop2的server.properties中
broker.id=1
#修改hadoop3的server.properties中
broker.id=2(6).编写kafka脚本
#进入bin目录下:
cd ~/bin
#创建脚本:
vi kf.sh内容如下:
#!/bin/bash
case $1 in
"start"){
for i in hadoop1 hadoop2 hadoop3
do
echo " --------启动 $i Kafka-------"
ssh $i "/root/soft/kafka/bin/kafka-server-start.sh -daemon /root/soft/kafka/config/server.properties "
done
};;
"stop"){
for i in hadoop1 hadoop2 hadoop3
do
echo " --------停止 $i Kafka-------"
ssh $i "/root/soft/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
#添加脚本执行权限:
chmod u+x kf.sh
(7).启动kafka集群
启#动kafka集群需要先启动zookeeper集群:
zk.sh start | kf.sh start
使用jps查看三台机器的节点是否启动:jps



#关闭kafka集群:
kf.sh stop
(8).kafka集群的简单使用
#启动kafka集群:
kf.sh start
#进入kafka目录:
cd $KAFKA_HOME
#查看kafka topic列表:
bin/kafka-topics.sh --zookeeper hadoop1:2181/kafka --list
#创建topic:
bin/kafka-topics.sh --zookeeper hadoop1:2181/kafka \
--create --replication-factor 3 --partitions 1 --topic demo
#删除topic:
bin/kafka-topics.sh --zookeeper hadoop1:2181/kafka \
--delete --topic demo
#发送消息:
bin/kafka-console-producer.sh \
--broker-list hadoop1:9092 --topic demo
#消费消息:
bin/kafka-console-consumer.sh \
--bootstrap-server hadoop1:9092 --from-beginning --topic demo
#查看某个topic的详情:
bin/kafka-topics.sh --zookeeper hadoop1:2181/kafka \ --describe --topic demo
#修改分区数:
bin/kafka-topics.sh --zookeeper hadoop1:2181/kafka --alter --topic demo --partitions 6



